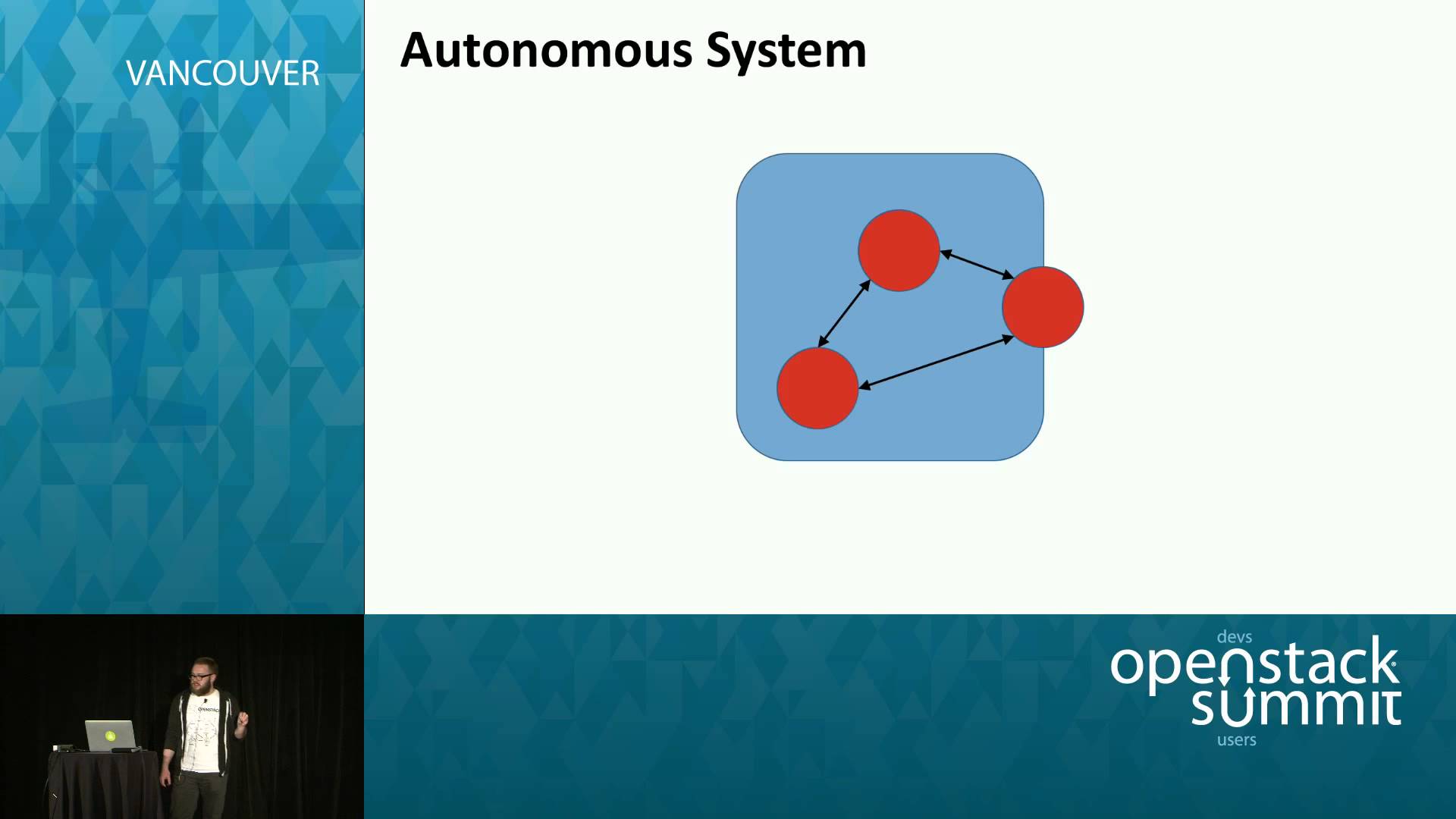
Service high-availability is a core concern for any operator running, or intending to run, a production OpenStack cluster. Current “best practices” call for the deployment of a full cluster stack (generally Corosync + Pacemaker) and / or load-balancers (generally HAProxy) to manage service state and failover. While this is appropriate for a subset of OpenStack services it unnecessarily adds complexity to many others.
…Full session details here: